
This isn’t hyperbole: we have some big counterintuitive revelations coming on #MartechDay 2024
If you only attend one online event this year… well, then it's clearly not 2021 anymore! 😀 But this one is worth it. I guarantee you will be surprised, if not shocked, by what we share. On Tuesday, May 7, Frans Riemersma and I will host our annual #MartechDay celebration. We'll release the epic 2024 martech landscape. We'll publish a deeply researched State of Martech report. We'll host the 2024 Stackie Awards. And we'll interview […]
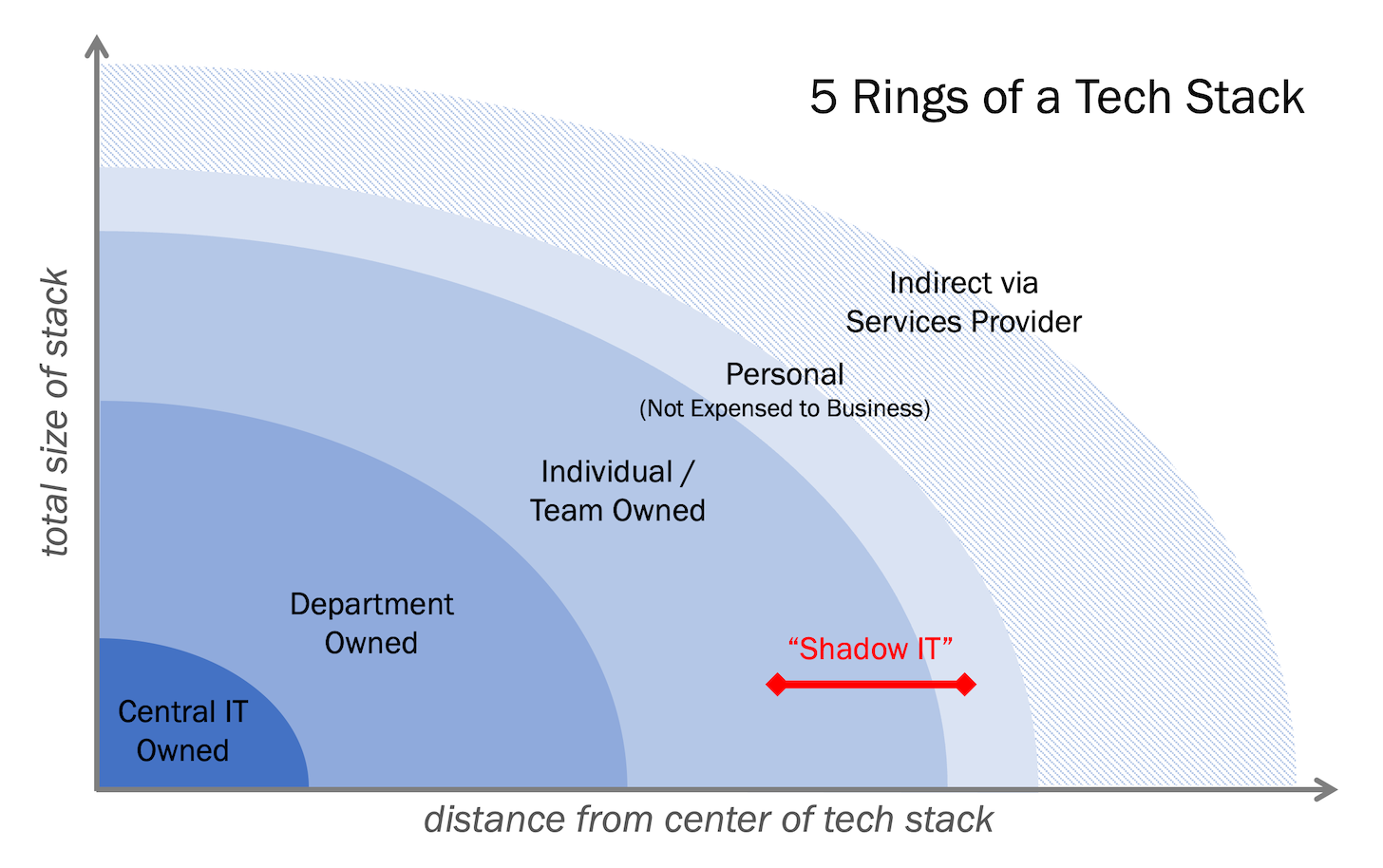
Visible and invisible tech stacks, and the upsides and downsides of “shadow IT” in martech and beyond
Tech stacks are large. The empirical stack data we recently shared from Zylo, a leading SaaS management platform, showed that even after a year of belt-tightening, the average SMB (500 employees or […]
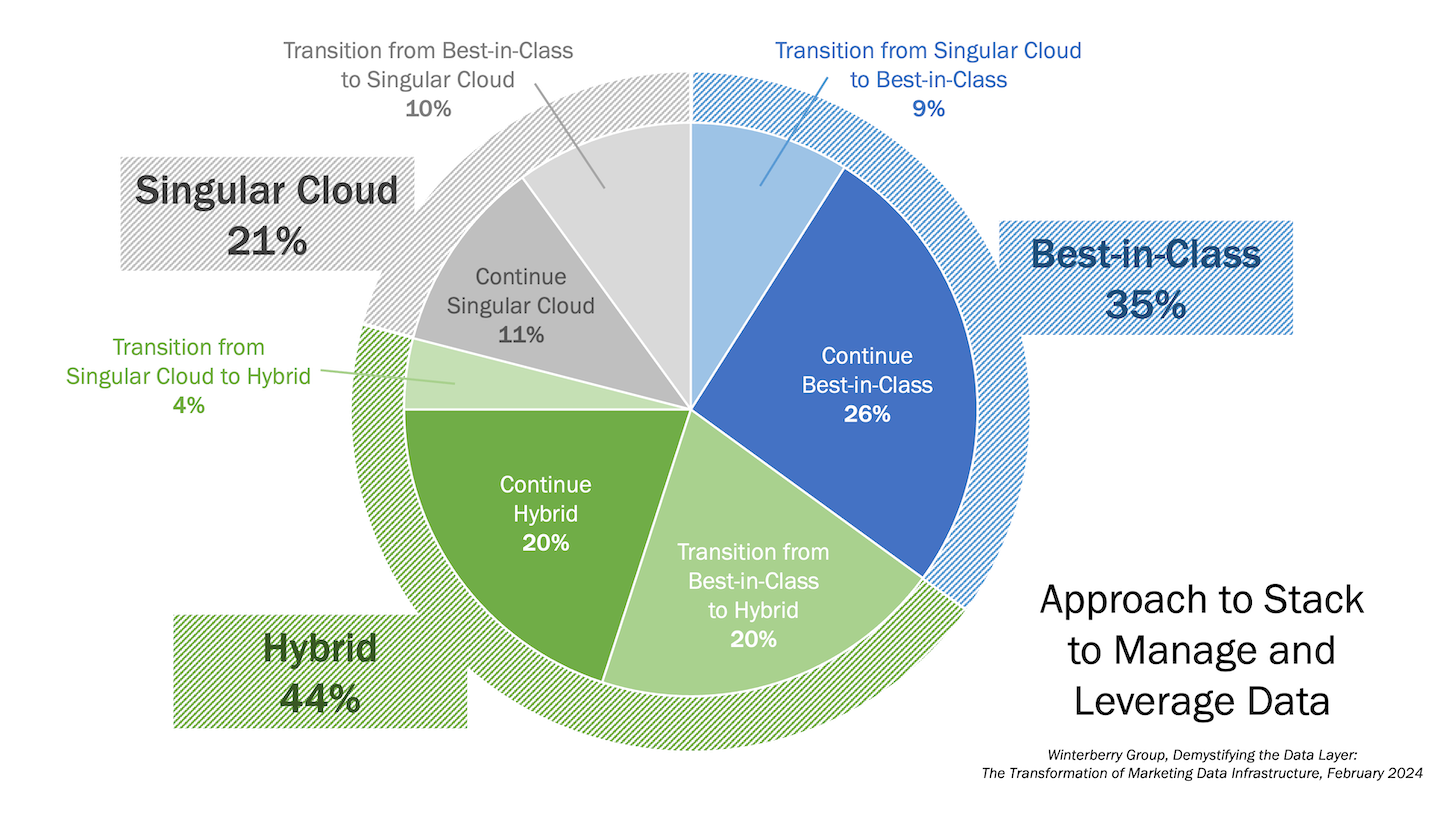
Can martech data be unified, federated, and siloed all at the same time? Yes, and each serves a purpose
First, one more reminder: please take our Martech Composability Survey this week. When you see the questions, I think you'll agree that having a statistically significant dataset for a "no BS" view […]
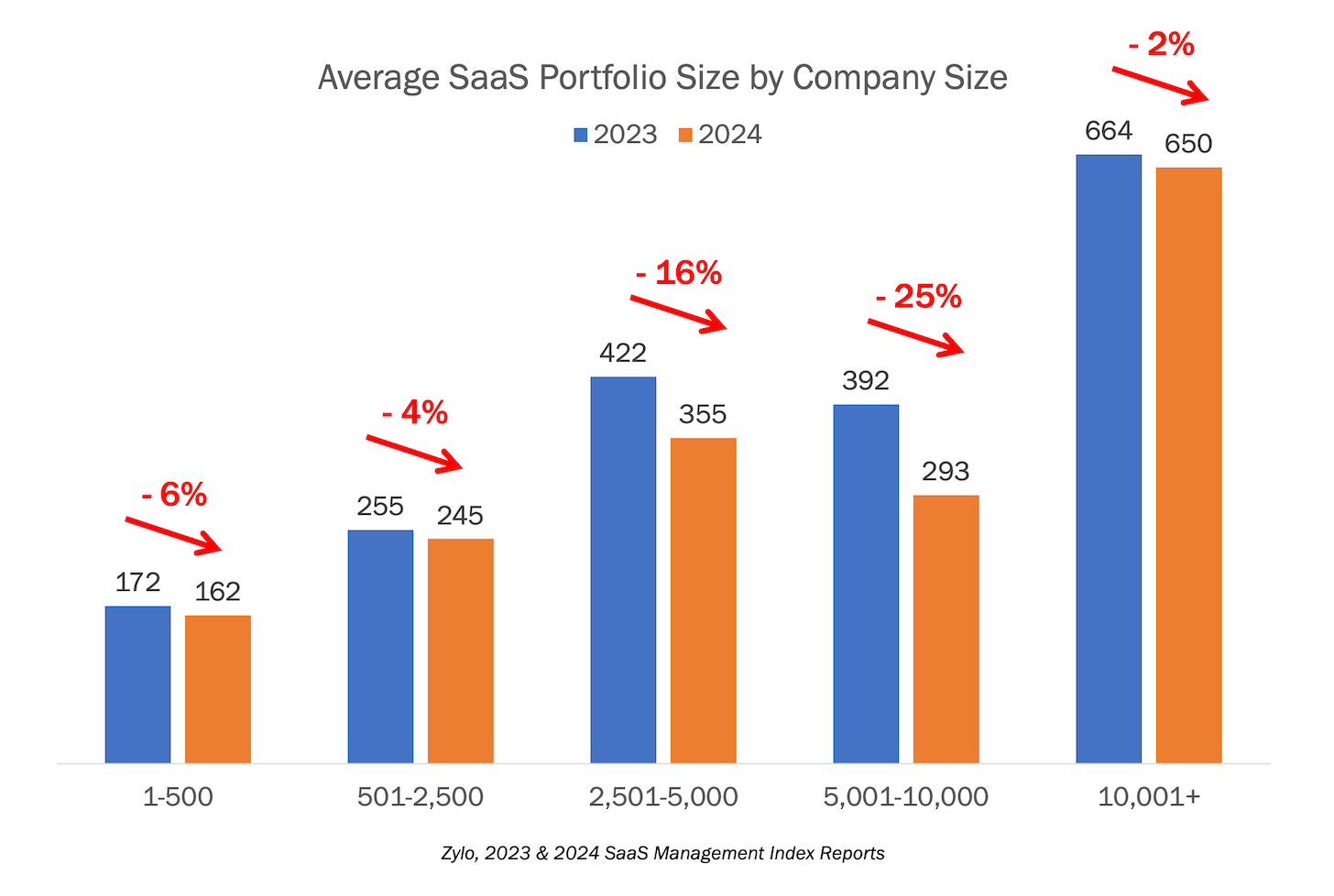
Well, SaaS tech stacks shrank from 2023 to 2024… but only by 8%. You were expecting more?
First, a quick ask: please take this 5-minute survey on martech composability. We'll share the full results back with everyone. I bet it will be very interesting. Thank you! Okay, back to […]
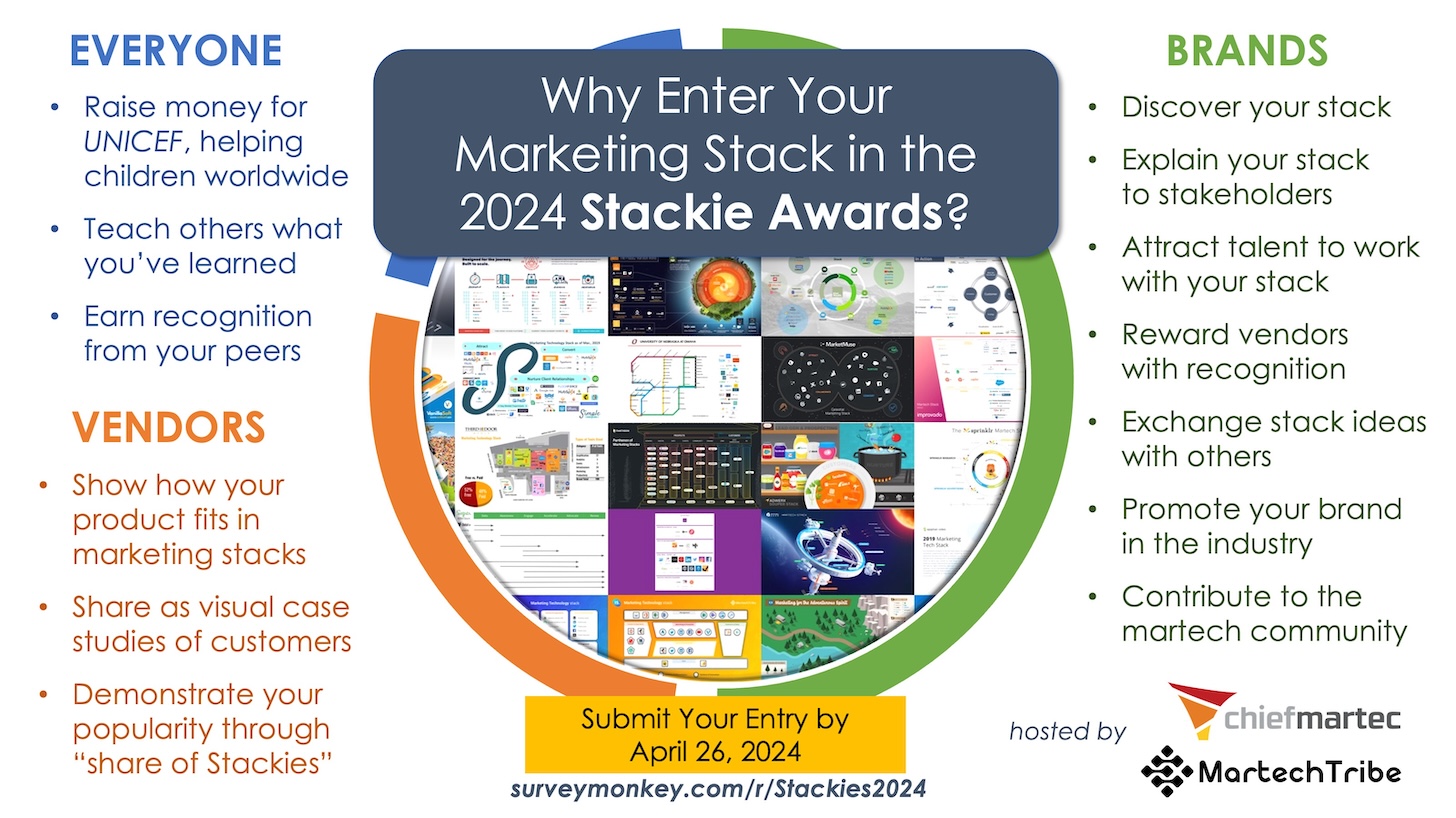
The 2024 Stackie Awards are now open for entries — share a slide of your martech stack, everybody wins
It's that time of the year. The Northern hemisphere looks forward to spring. The Southern hemisphere looks forward to fall. And everybody in martech and marketing operations looks forward to the annual […]
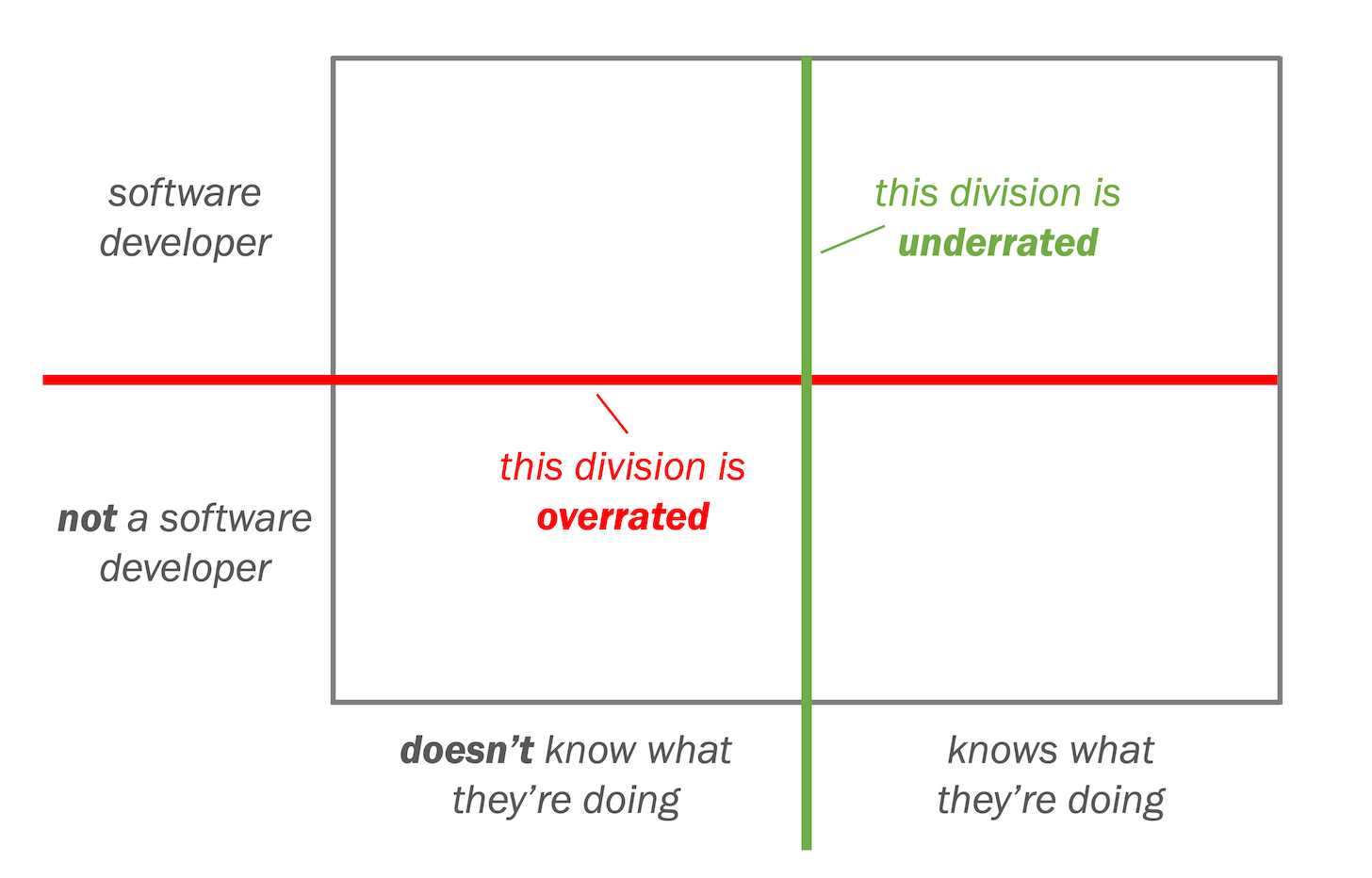
Developer vs. non-developer is the wrong divide; what matters with no-code is knowing what you’re doing
Dear marketing readers: hang in with me here. I have a point. Promise. I started programming as a kid, writing multiplayer games for dial-up bulletin board systems (BBSs) — a precursor to […]
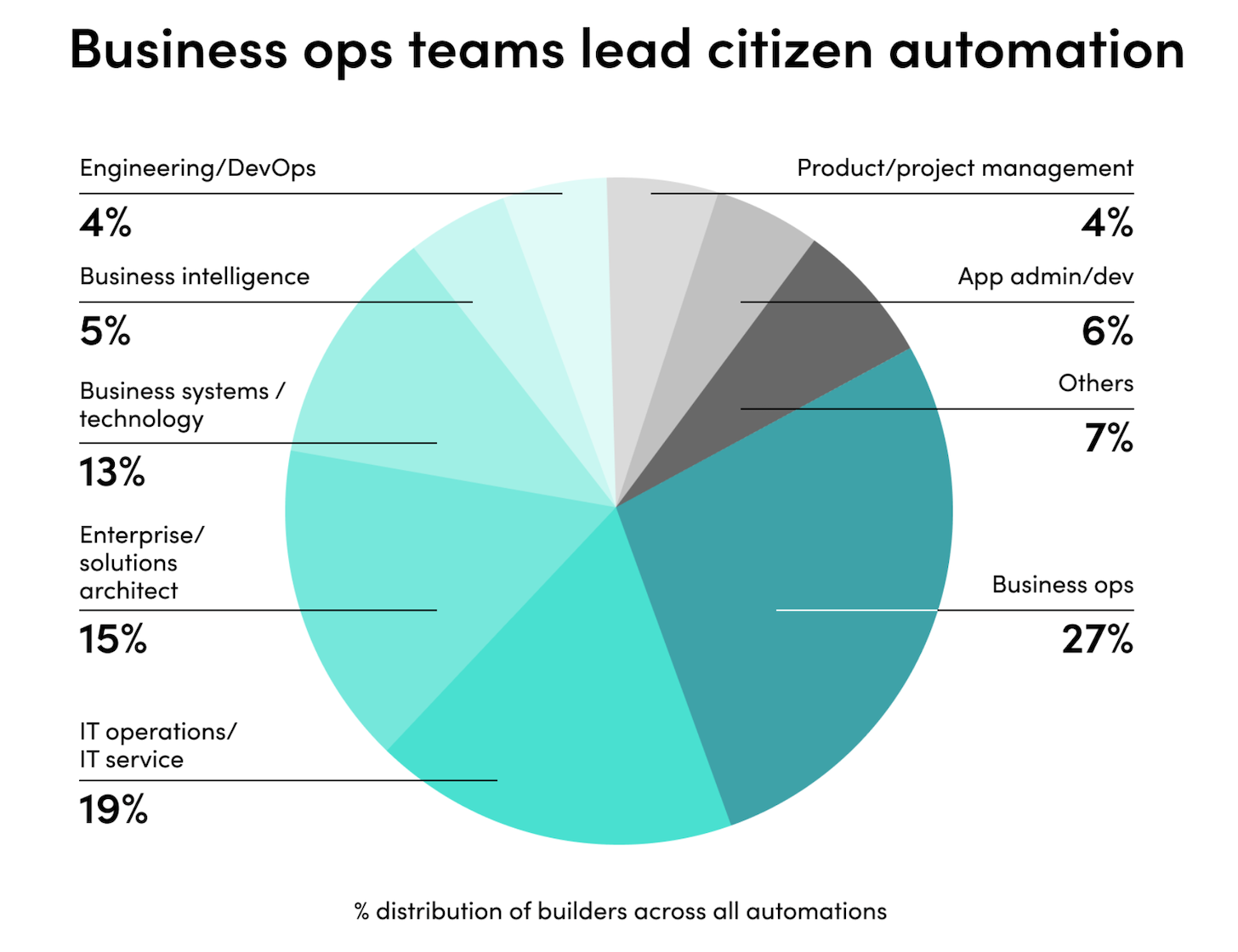
Every marketer a data analyst and an engineer… delusion or destiny?
"Everyone within Publicis will become a data analyst, an engineer, an intelligence partner, with all the information they need at their fingertips to supercharge client growth." Publicis Groupe made that bold statement […]
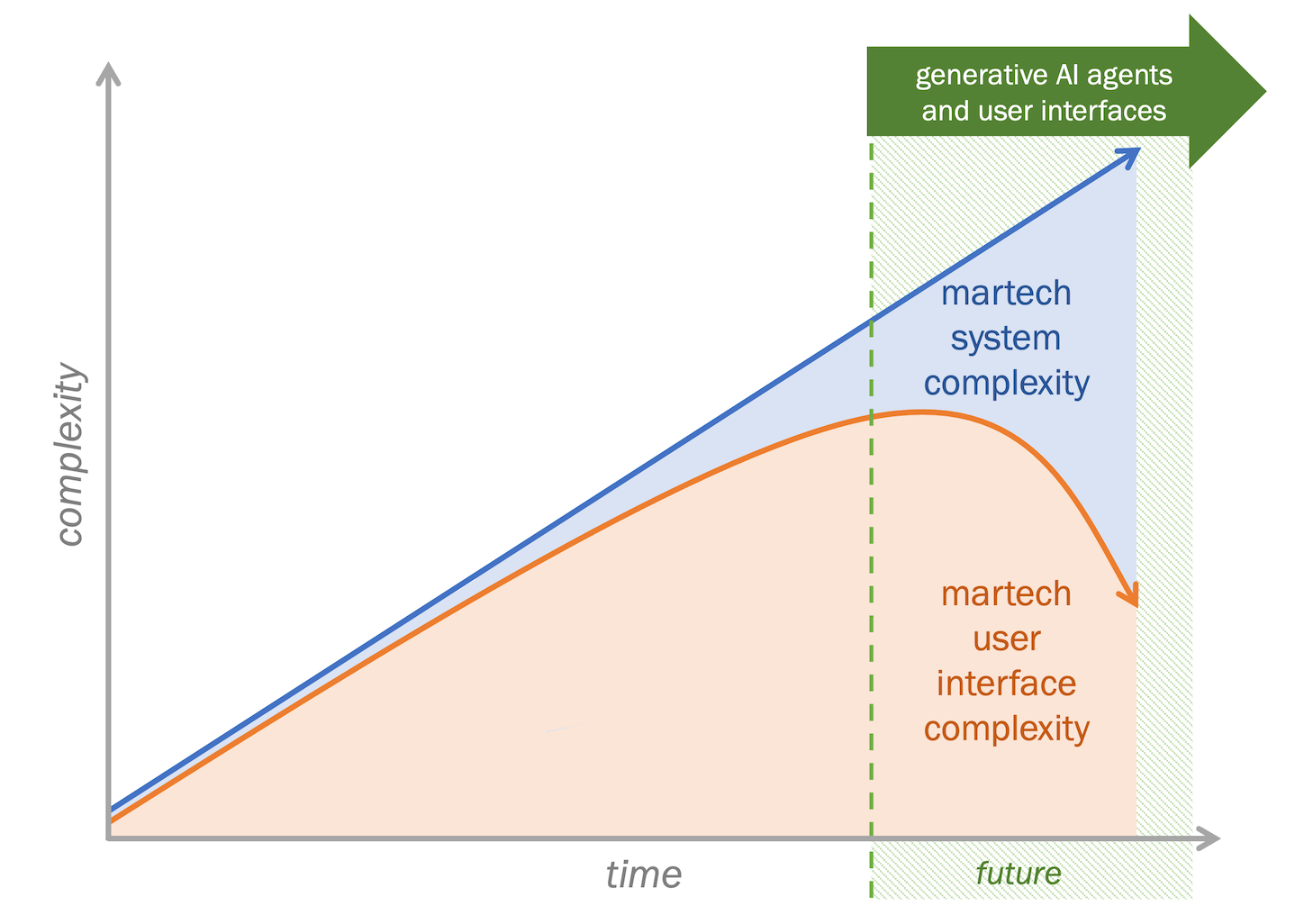
The amazing turning point when martech systems complexity and martech UX complexity diverge
Welcome to 2024! I expect this will be a transformative year in martech. The Martech for 2024 report we published last month (video presentation) covered several of the major trends underway, such […]

Missed our Martech for 2024 jam session? Catch the replay and get the 89-page report for free
Last week, Frans Riemersma and I published our Martech for 2024 report, an in-depth analysis of the evolving martech landscape in the gen AI era and the underlying forces of aggregation and […]

Major trends in martech for 2024: the real changes underway in a 99% platitude-free report
There was a meme circulating around social media last week of an agency marketer rambling in a "thought leadership" interview on TikTok. I have no idea if it was parody or real. […]

What will happen in martech in 2024? A no-BS report and webinar by two giant martech nerds
Want to know what 2024 has in store for martech? I'm not talking about wild-eyed, hand-wavy, link-baity prognostications that proliferate in every year-end prediction season like that one Mariah Carey Christmas tune. […]
Check Out Hacking Marketing on Amazon

A brilliant road map on how to evolve the capability and culture of marketing practices using parallels from the most disruptive industry in the world, the software industry.
Ram Krishnan, SVP & CMO, PepsiCo
Interviews

Start 2017 with the world’s most famous chief marketing technologist
Happy New Year, dear readers! What better way to launch into 2017 than revisiting our […]

Digital transformation at the AARP, from old to new
Had your fill of millennial marketing articles lately? Even the millennials themselves are like, "Don't […]

Insights from the chief marketing technologist of an $18B firm
Duane Schulz, chief marketing technologist at Xerox, is a marketing technologist's marketing technologist. One of […]

How utilized is marketing automation today? An expert weighs in
I recently had the chance to talk with Jeff Pedowitz, the founder and president of […]
Marketing
This isn’t hyperbole: we have some big counterintuitive revelations coming on #MartechDay 2024
If you only attend one online event this year… well, then it's clearly not 2021 […]
Visible and invisible tech stacks, and the upsides and downsides of “shadow IT” in martech and beyond
Tech stacks are large. The empirical stack data we recently shared from Zylo, a leading […]
Can martech data be unified, federated, and siloed all at the same time? Yes, and each serves a purpose
First, one more reminder: please take our Martech Composability Survey this week. When you see […]
Well, SaaS tech stacks shrank from 2023 to 2024… but only by 8%. You were expecting more?
First, a quick ask: please take this 5-minute survey on martech composability. We'll share the […]
Media Content

The Martech Show Episode #11: The Great Unbundling with Benedict Evans
The Martech Show is back! Our latest episode is an interview with Benedict Evans, tech […]
The Martech Show Episode #10: Lessons from a Fortune 50 CMO on Agile Marketing, Martech & More
Season #1 of The Martech Show concludes in Episode #10 with a terrific conversation with […]

The Martech Show Episode #9: The Tech-Savvy CMO — Unicorn or Universal?
For this 9th episode of The Martech Show, I was delighted to have Rishi Dave, […]
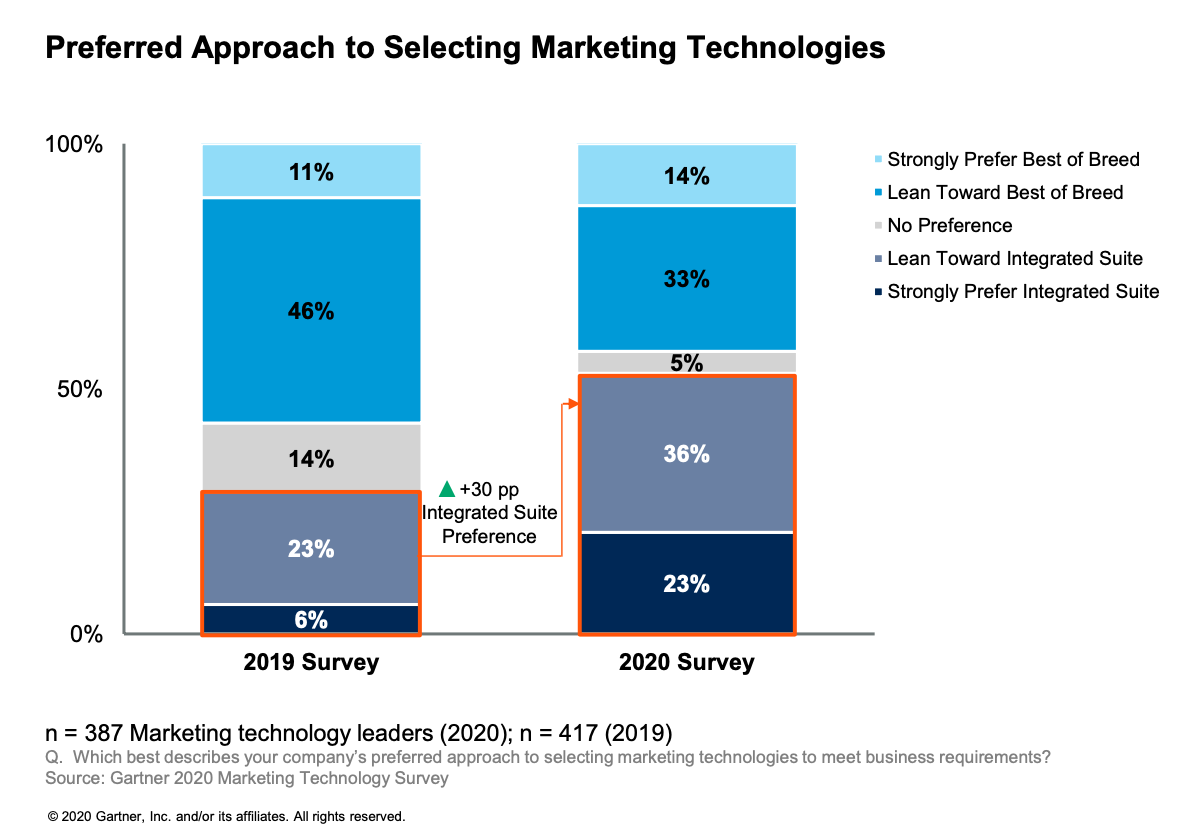
The Martech Show Episode #8: The Martech Suite Strikes Back?
Ben Bloom, a senior research director at Gartner who specializes in marketing technology management, joined […]